Cognitive Offloading: A System for What to Keep in Your Head and What to Delegate
I carried a notebook in my back pocket for years. These were ratty little things - usually held together with Gaffers tape. I called it the butt book, because that’s where it lived. The idea was simple: whenever something worth remembering surfaced, I’d write it down before it disappeared.
It worked, for capture. The ideas made it onto paper. The crisis of “I just had a thought and now it’s gone” happened less often. But the notebooks accumulated, and the ideas inside them became a graveyard. If I remembered to go back and find something — and that’s a significant “if” — I still had to locate it, interpret my own handwriting, and reconstruct whatever context made the idea seem worth writing down in the first place.
The capture problem was solved. The retrieval problem never was.
Every system I tried solved the same half of the problem
Evernote. Obsidian. Apple Notes. Todoist. Each one promised a different organizational model — tags, backlinks, smart folders, natural-language reminders. Each one worked for about two weeks, which is roughly how long it takes for a structured environment to get out of whack when you have (undiagnosed!) ADHD and the system requires you to maintain it. The failure modes are structural, not motivational.
The pattern was always the same: set it up, use it enthusiastically, let it drift, watch the structure collapse under its own weight, abandon it for the next thing. Not because the tools were bad — because they all assumed I’d come back to them. Every system required me to initiate retrieval. To remember that I’d stored something, navigate to where I’d stored it, and find it among everything else I’d stored.
That’s three cognitive tasks before you even get to the information you need. For someone whose working memory is the bottleneck, that’s three chances to lose the thread.
Notion is the exception, but only because I use it exclusively for school and keep it aggressively structured. Tight scope, rigid templates, no room to drift. It works precisely because I don’t let it become a general-purpose system.
So I built one
Before the current wave of AI tools, I built a thing called GetRamble. It has a phone number. I can text it at any time — in line at the grocery store, in the middle of a meeting, at 2am — and OpenAI’s API would turn my stream of consciousness into categorized notes.
My kids would ask who “ramble” was because I said it so often: “Hey Siri, text ramble.”
It worked. Really well, actually. I was still using it as recently as a few months ago. The capture problem and the categorization problem were both solved — text a rambling thought, get back structured, searchable notes.
But Ramble stalled, for reasons that will sound familiar if you’ve read what I write about governance.
I was building it with a combination of my own work and Replit. Replit couldn’t stay sane — the same ungoverned-architecture problem I’ve since built an entire methodology around solving. Eventually, it became more work to wrangle the features than to get results, and I didn’t have the bandwidth to rewrite it myself. Full-time job, school, wife, two kids. The 10DLC compliance burden alone — the regulatory framework for application-to-person messaging — was a part-time job for a one-person team.
I wanted to monetize it. But without capital and a testing cohort, I couldn’t release it into the wild. The product was good. The architecture wasn’t stable enough to trust — and at the time, I didn’t have a word for what was missing. I just knew I couldn’t ship something I’d have to maintain at 2 am when it broke in ways I couldn’t predict.
Will I finish it? Probably not — I have better tools now. But the experience was formative. It’s part of where my governance methodology comes from. I built something that worked, and watched it collapse not because the idea was wrong, but because the system around it couldn’t hold.
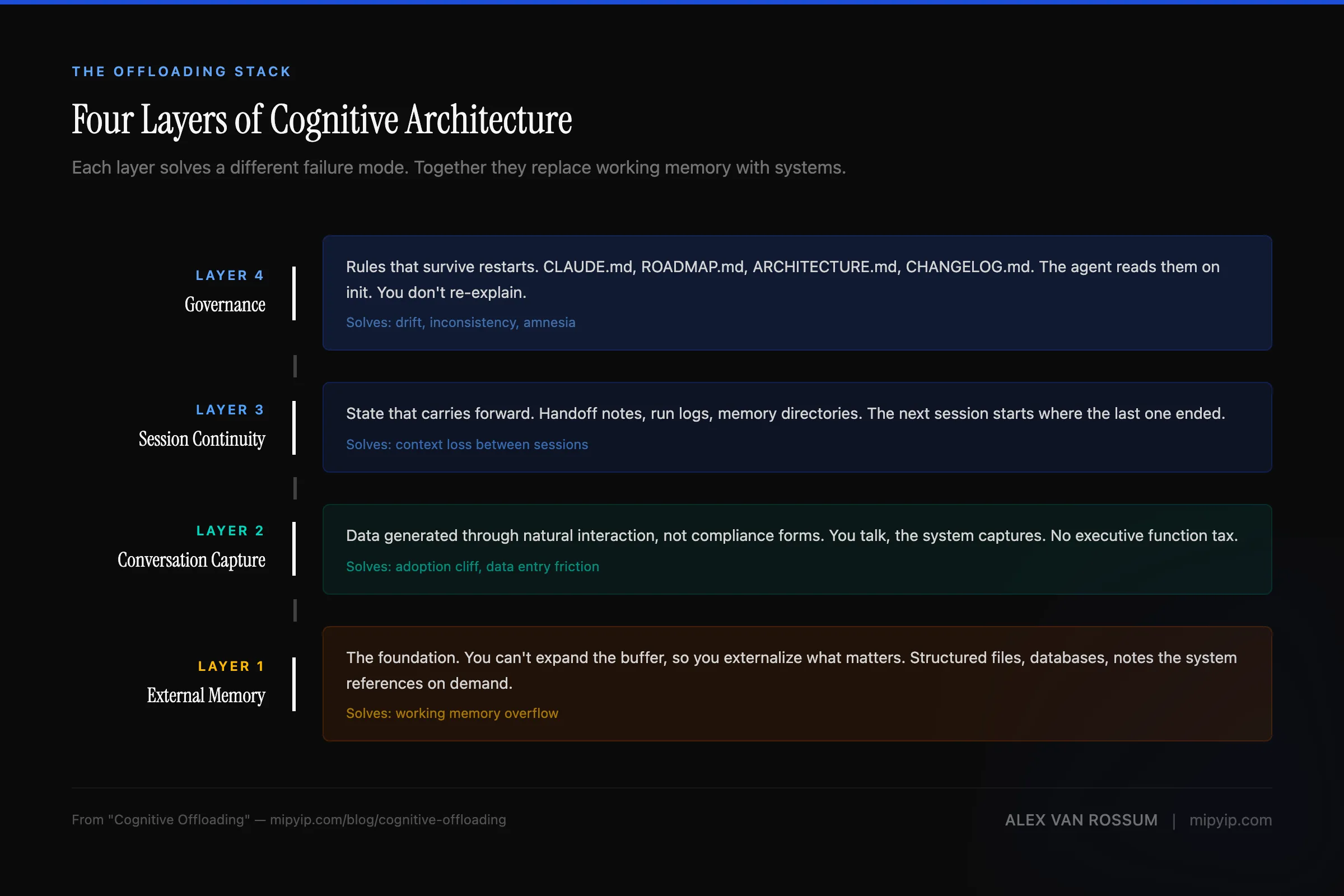
What changed wasn’t the tool — it was the architecture
Claude Code didn’t solve the capture problem better than Ramble. It solved a different problem entirely: it made retrieval automatic.
Every previous system — analog or digital, simple or AI-powered — required me to go get the information, remember I’d stored something, navigate to it, and load it back into working memory. Claude Code’s governance documents flipped that model. The agent reads its own state at the start of every session. I don’t retrieve. The system loads.
That distinction is the whole thing.
The plan exists, it’s maintained, it’s comprehensive — but it never demands my attention. It’s there when I need it and invisible when I don’t. I can forget it exists and still follow it, because the system is holding the state, not me.
Three things make this work in practice:
Project-level state persistence. Each project maintains its own context through governance documents. I can revisit any project at any time and get an immediate snapshot — not by reading through files myself, but by asking the agent what’s current. The project’s memory survives the session boundary because it was designed to.
Rapid idea triage. When an idea surfaces now, I don’t write it in a notebook and hope I’ll find it later. I spin up a prototype — Excalidraw wireframe, governance templates, a solid directive — and within a single conversation, I know whether the idea has legs. If it does, it gets filed into my project management system with full context attached. If it doesn’t, it gets archived cleanly. Either way, it’s out of my head and into a system that can hold it without my participation. The cognitive cost of exploring an idea dropped from “a weekend” to “a conversation.”
A personal project manager that doesn’t require me to manage it. I run a lightweight environment that stores the state of everything I’m tracking — a set of JSON index files with descriptions pointing to full markdown files for detail. No RAG, no vector database. A poor man’s index that works because the scope is deliberate and the governance is tight. It started as a scratchpad within another project and became a standalone system when the separation of concerns demanded it.
Choosing what stays in your mind
Cognitive offloading is the deliberate process of choosing what stays in your mind and building systems to handle the rest.
Not productivity hacking. Not “getting organized.” Architecture — designed to match how your brain actually operates rather than how productivity systems assume it should.
The butt book was cognitive offloading. Ramble was cognitive offloading. But they were incomplete implementations — they solved capture without solving retrieval, so the offloaded information ended up in cold storage with no mechanism to bring it back when it mattered.
What I’m building now is the complete architecture: capture, categorization, persistence, and automatic retrieval. The information flows out of my head and into governed systems that carry it forward — not just storing it, but delivering it at the right time, in the right context, without requiring me to remember it exists.
The background anxiety lifts. Not because the work is less important, but because I’m no longer the one responsible for holding it all. The system holds it. I think about whatever is actually in front of me.
That’s not a productivity gain. That’s an architectural change in how I allocate cognitive resources — and it turns out it applies to AI agents the same way it applies to human brains, because the failure modes are structurally identical.
If your system requires you to remember to use it, it’s not offloading anything. It’s just adding a task.
Cognitive offloading is the methodology behind Pass@1 and the governance documents. For the architectural argument: Governance Is Architecture. For how this applies to agent management: Managing Agents Like Teams. For the ownership question these patterns raise: Cognitive Property. If you’ve been building similar systems, I’d like to hear about it.
If you’re thinking about how to apply this at an organizational level, the AI readiness diagnostic shows where your team’s current architecture supports this kind of offloading — and where it doesn’t.
Or get new posts in your inbox
Occasional writing on systems, ADHD, and AI. No cadence pressure.
You're in. I'll send you the next one.