The Governance Documents
Start a Claude Code session without governance documents, and you’ll spend the first twenty minutes getting the agent oriented. It re-reads the codebase. It might ask questions you already answered yesterday. It makes architectural choices that contradict decisions from last week. By the time it’s ready to write code, you’ve either burned a quarter of the context window on setup that should have been spent on actual work, or you’ve suffered multiple compactions, and you’re even worse off than before.
But if you start the same session with governance documents — CLAUDE.md, ROADMAP.md, ARCHITECTURE.md, CHANGELOG.md — the agent picks up where the last session left off. Same conventions. Same patterns. Same awareness of what broke last time and how it was fixed. (You can use a named replacement for other agents, such as GEMINI.md, or a generic core file, such as AGENT.md, as the core directives. I have found that the results are less structured with other agents.)
That difference is the entire methodology. Pass@1 isn’t about prompting. It’s about these four files.
The spec the agent builds against
ROADMAP.md is the contract. Not a backlog of ideas. Not a wish list with priorities. It’s the spec — what to build, in what order, with what constraints.
When a roadmap entry says “add floating popout buttons — persistent, always-on-top, position remembered across restarts, click to run,” the agent has everything it needs to start building. No Slack thread to check. No product manager to interpret. No ambiguity about what “done” means.
I’ve built what happens when the roadmap is vague. “Improve the settings page” produces a different interpretation every session. The agent makes reasonable choices — they’re just different reasonable choices than the ones from yesterday, and different from the ones it’ll make tomorrow. The roadmap eliminates that variance by being specific enough that correctness is verifiable.
The roadmap also functions as a priority system. What’s in the current sprint gets built. What’s in the backlog waits. This sounds obvious until you’ve watched an AI agent enthusiastically refactor your authentication system when you asked it to fix a CSS bug — because without explicit priorities, everything looks equally important.
The boundaries the agent works within
ARCHITECTURE.md defines how the system is built. Not what it does — how the pieces connect, where the boundaries are, and what patterns to follow.
In my Electron apps, the architecture document specifies that all IPC goes through the preload bridge and the renderer never touches Node.js APIs. That’s not a suggestion. It’s a constraint. When the agent needs to add a feature that requires filesystem access, it doesn’t invent a shortcut through the security boundary — it routes through the bridge, because the architecture document says that’s how this system works.
Without the architecture document, every session is a negotiation. The agent reads the codebase, infers patterns, and builds something consistent with what it found. Usually. But codebases accumulate exceptions, and an agent that infers patterns from code that includes both the “right way” and three legacy workarounds will sometimes pick the wrong pattern to follow.
The architecture document cuts through that ambiguity. It doesn’t say “this is how it seems to work.” It says, “This is how it works. Follow this.”
The memory that survives between sessions
CLAUDE.md is the governance document that changed my workflow the most.
AI agent sessions are ephemeral. The context window compacts. The session ends. The next session starts fresh with no memory of what happened before. Every hard-won insight about the codebase, every gotcha discovered through debugging, every convention established through trial and error — gone.
CLAUDE.md is persistent working memory. It carries forward everything the next session needs to know: coding conventions, known gotchas, patterns that work, patterns that failed, file locations, architectural decisions and their rationale.
A concrete example. This website project’s CLAUDE.md has a section called “Already Solved — Don’t Re-investigate.” It includes entries like: Tailwind v4’s translate property is independent of transform, so overriding translate-x-full requires resetting a CSS variable rather than using transform: translateX(0). Or: the mobile menu must live outside <header> because backdrop-filter creates a containing block for position: fixed children. Or: Astro module scripts and astro:page-load fire at the same tick, so don’t register event handlers in both.
This entire model is part of a methodology I call cognitive offloading — deliberately choosing what stays in your mind and building systems to handle the rest. The governance documents aren’t just agent infrastructure. They’re the offloading mechanism — the system that lets you stop holding project state in your head and trust that it’s captured, versioned, and delivered to the next session automatically. They’re also, it turns out, cognitive property — transferable, reproducible encodings of how you reason.
Each of those cost a debugging session to figure out the first time. Without the CLAUDE.md entry, the next session hits the same problem, spends the same time, and “solves” it the same way — or worse, solves it differently, introducing an inconsistency.
The most underrated function of CLAUDE.md is what I call the culture document effect. AI agents conform to whatever standards they find in their context. If your CLAUDE.md says “use camelCase for functions, PascalCase for components, SCREAMING_SNAKE for constants,” the agent follows that convention reliably. If it says nothing, the agent guesses — and it sometimes guesses differently every new session.
This is the same dynamic as onboarding a new hire. You wouldn’t drop someone into a codebase and say “just start building.” You’d hand them the style guide, the architectural overview, the list of things that are broken and why. CLAUDE.md is the onboarding document, delivered fresh at the start of every session to an agent who might not have any prior experience working here.
But what about MEMORY.md? Claude Code maintains its own internal memory file (MEMORY.md) under
~/.claude/in your home directory. It’s automatic, it works well, and you don’t — or shouldn’t — have direct control over it. But it’s local to the machine and not version-controlled. If you start a fresh session after compaction, switch machines, or lose your local environment, that memory is gone. Without a governance document committed to the repo itself, you’re starting from scratch every time.
The running record
CHANGELOG.md tracks what’s been built and what’s changed. It’s the project’s institutional memory — the audit trail that prevents regression.
After each block of work, the changelog gets updated. Not as a nice-to-have, but the mechanism that prevents the next session from accidentally reverting a decision or re-implementing something that was already tried and rejected.
The changelog also serves a subtler function: it makes the agent aware of the project’s trajectory. When the agent can see that the last ten entries were security hardening work, it’s less likely to introduce a pattern that undermines that trajectory. Context shapes behavior, and it does so for AI agents the same way it shapes behavior for human developers.
The discipline nobody wants to hear about
The documents only work if they’re maintained. This is the part that separates Pass@1 from good intentions.
Every session that makes code changes must end with document updates. ROADMAP.md gets its sprint status updated. CHANGELOG.md gets new entries. CLAUDE.md gets new gotchas and solved problems. ARCHITECTURE.md gets updated if patterns or data models have changed. This isn’t optional. It’s the cost of maintaining the system that makes everything else work, and if the CLAUDE.md is structured properly, the agent will ensure it happens.
I’ve built this into the session workflow as a mandatory checklist — the last step before a commit. The discipline isn’t exciting. It’s the engineering equivalent of doing your dishes after cooking, rather than letting them pile up. But the compound effect over six months is significant: a project with maintained governance documents starts sessions faster, produces fewer bugs, and maintains consistency that would be impossible with session-to-session amnesia.
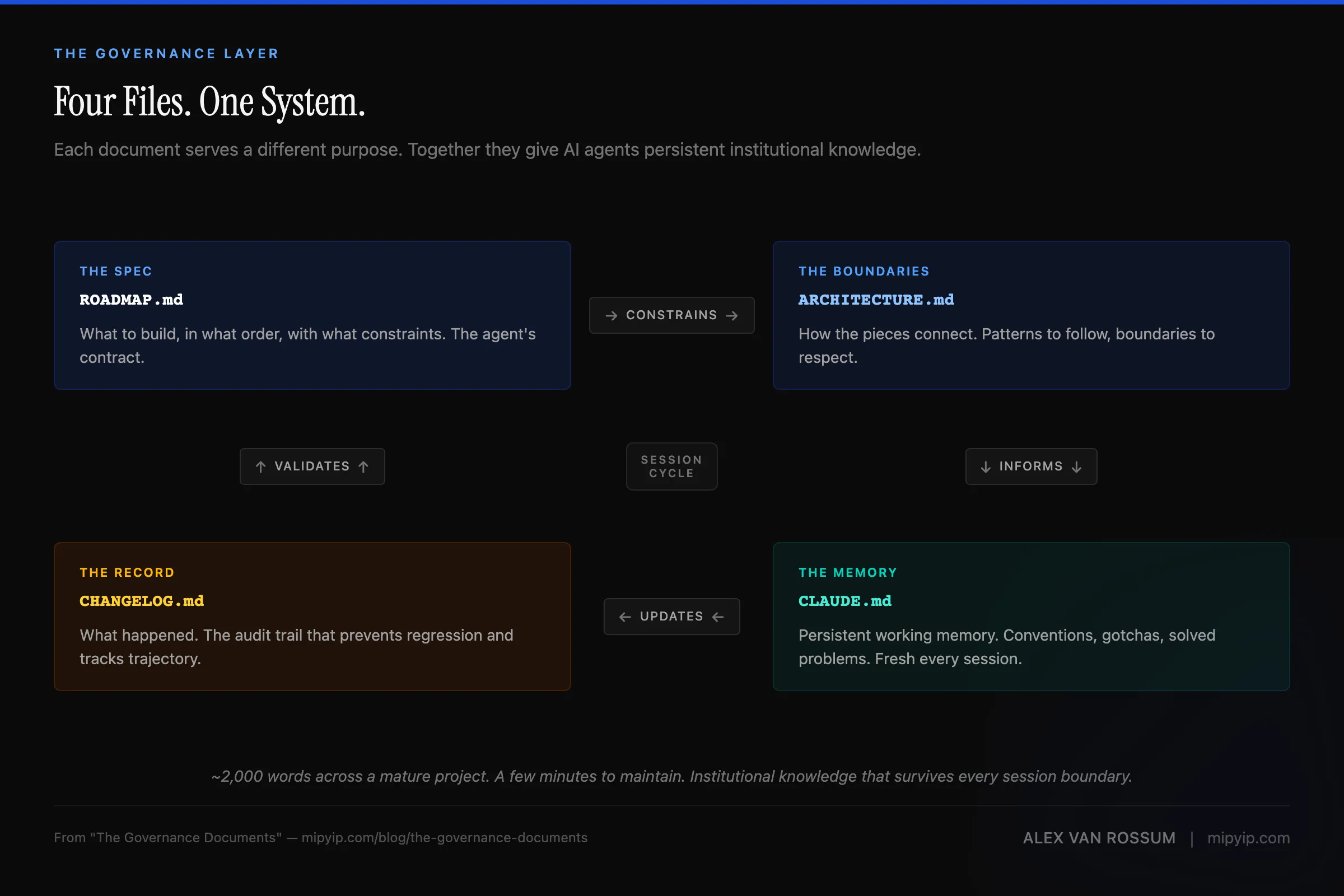
The governance layer
These four documents are the governance layer I consistently write about. They’re not project management artifacts bolted onto a development process. They’re engineering artifacts that make the development process possible.
Remove the governance documents, and the AI agent still generates code. It just generates code without memory, without constraints, without awareness of what came before. That’s not a prompting problem. That’s an architecture problem — and when it happens in a client-facing context, the consequences compound fast.
The four files total maybe 2,000 words across a mature project. The maintenance cost is a few moments at the end of each session. The return is an AI agent that operates with the institutional knowledge of every session that came before it — picking up exactly where the last one left off, respecting every convention, avoiding every solved gotcha. The results are measurable: this pattern drove an autonomous infrastructure agent that manages a production Kubernetes cluster and an AWS governance review that caught six figures in risk.
That’s not overhead, that’s the whole product.
This post is part of the Pass@1 series. For the methodology overview, see What Is Pass@1?. For the architectural argument, see Governance Is Architecture. For the ownership question these documents raise: Cognitive Property.
If you’re evaluating whether your organization’s technical foundation is built to support this kind of system, the CTO diagnostic scores you across eight domains — governance infrastructure included.
Or get new posts in your inbox
Occasional writing on systems, ADHD, and AI. No cadence pressure.
You're in. I'll send you the next one.